|
I got M.S. in Artificial Intelligence at College of Engineering in Seoul National University, where I'm advised by Prof. Nojun Kwak in the Machine Intelligence and Pattern Analysis Lab (MIPAL). Previously, I got my bachelor's degree at KyungHee University , where I majored in Computer Science and Engineering & International Studies. I'm interested in computer vision, machine learning, multimodality, video understanding. Email / Google Scholar / LinkedIn / Github |
|
|
|
Mar. 2026: New preprint on BM25-V: sparse visual word scoring for interpretable image retrieval. Oct. 2024: One paper is accepted to EMNLP 2024 Industry Track. Apr. 2024: One paper is accepted to CVPR 2024 Workshop on Efficient Large Vision Models. |
|
|


|
Donghoon Han, Eunhwan Park, Seunghyeon Seo Preprint, 2026 arxiv / project page We apply Okapi BM25 scoring to sparse visual words from a Sparse Autoencoder on ViT patch tokens, enabling efficient, interpretable image retrieval that matches dense accuracy via a two-stage pipeline. |
|
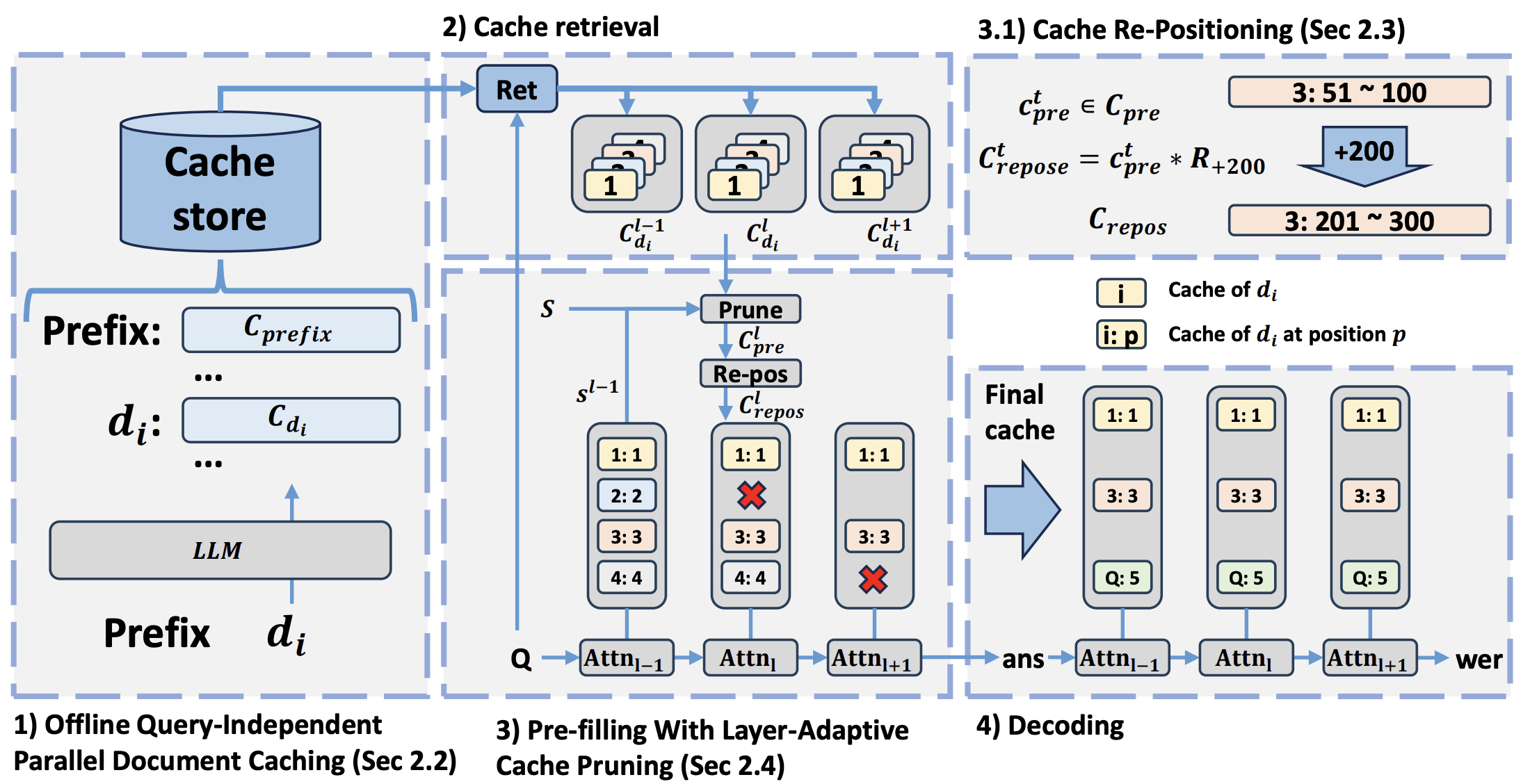
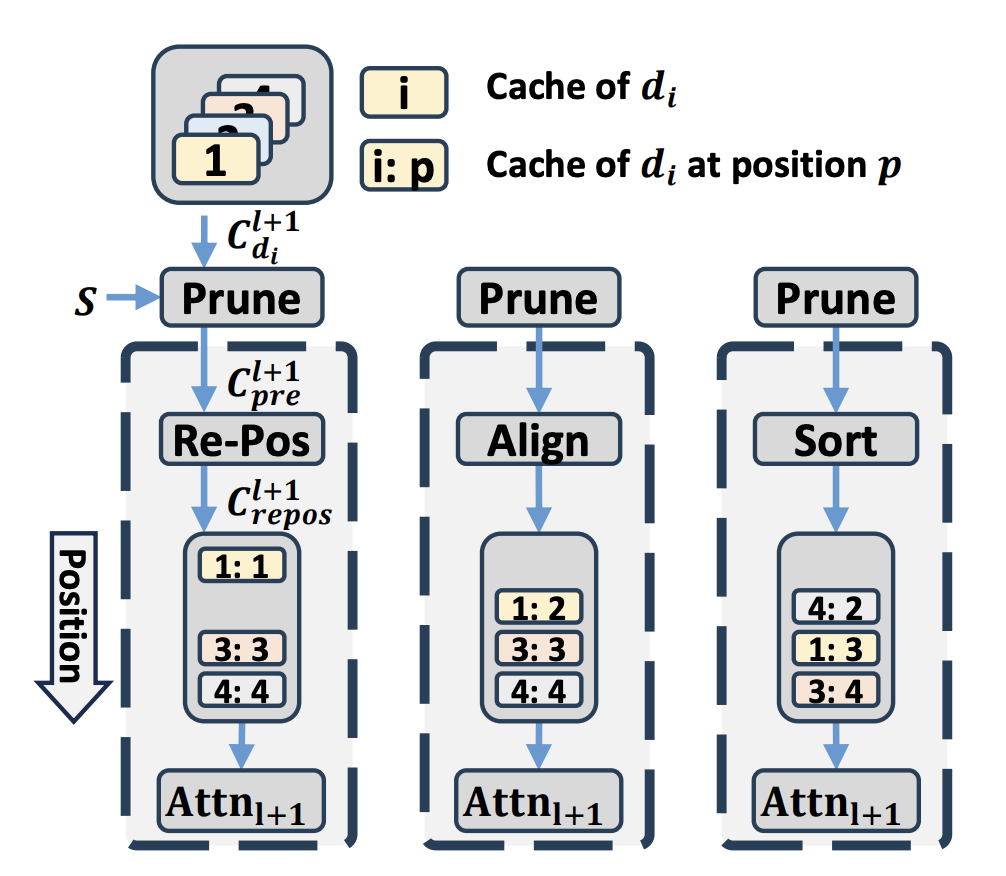
Kun-Hui Lee*, Eunhwan Park*, Donghoon Han, Seung-Hoon Na Under Review arXiv CacheFocus improves long-context handling in LLMs by optimizing cache reuse and reducing inference latency without additional training. It introduces Layer-Adaptive Cache Pruning and Adaptive Positional Allocation to enhance efficiency and mitigate performance degradation. Experiments show that CacheFocus outperforms existing methods, maintaining strong performance even with extended input lengths. |
|
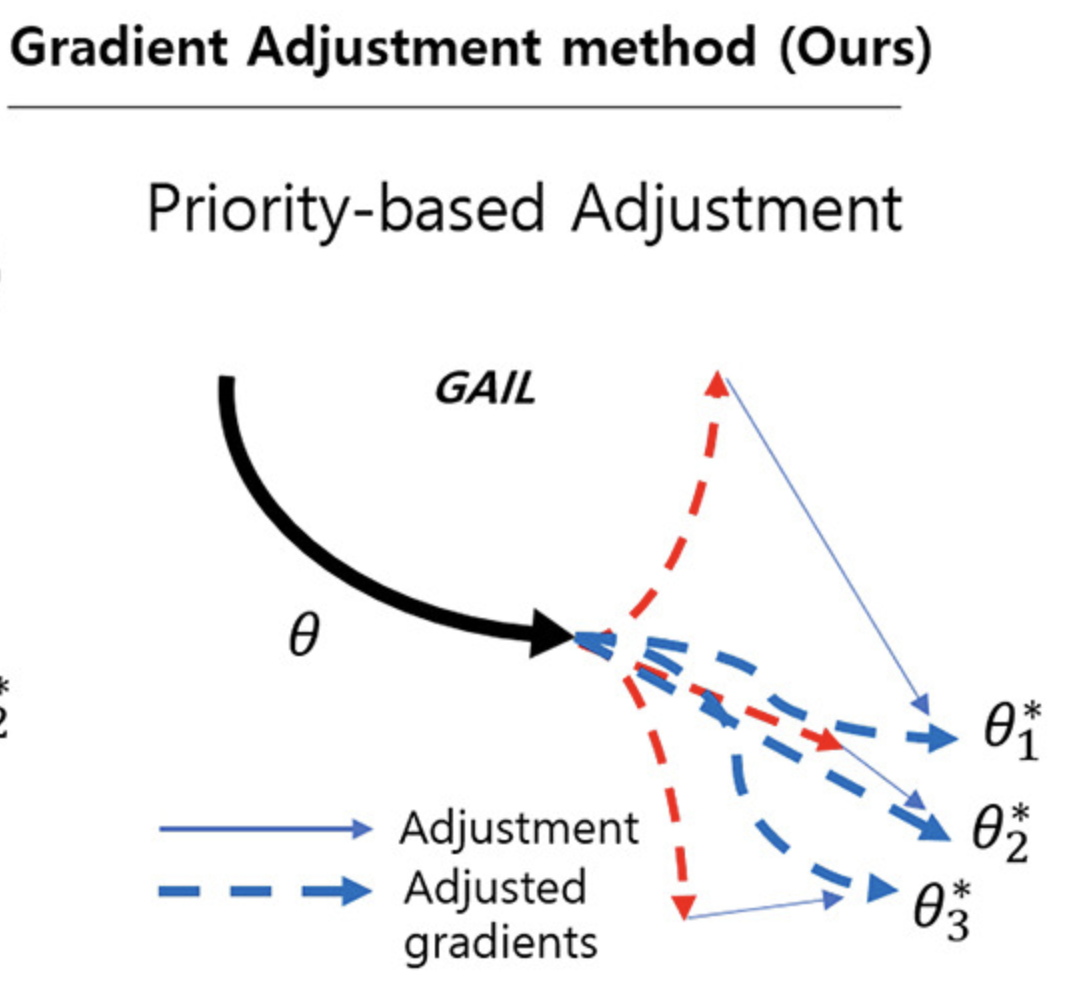
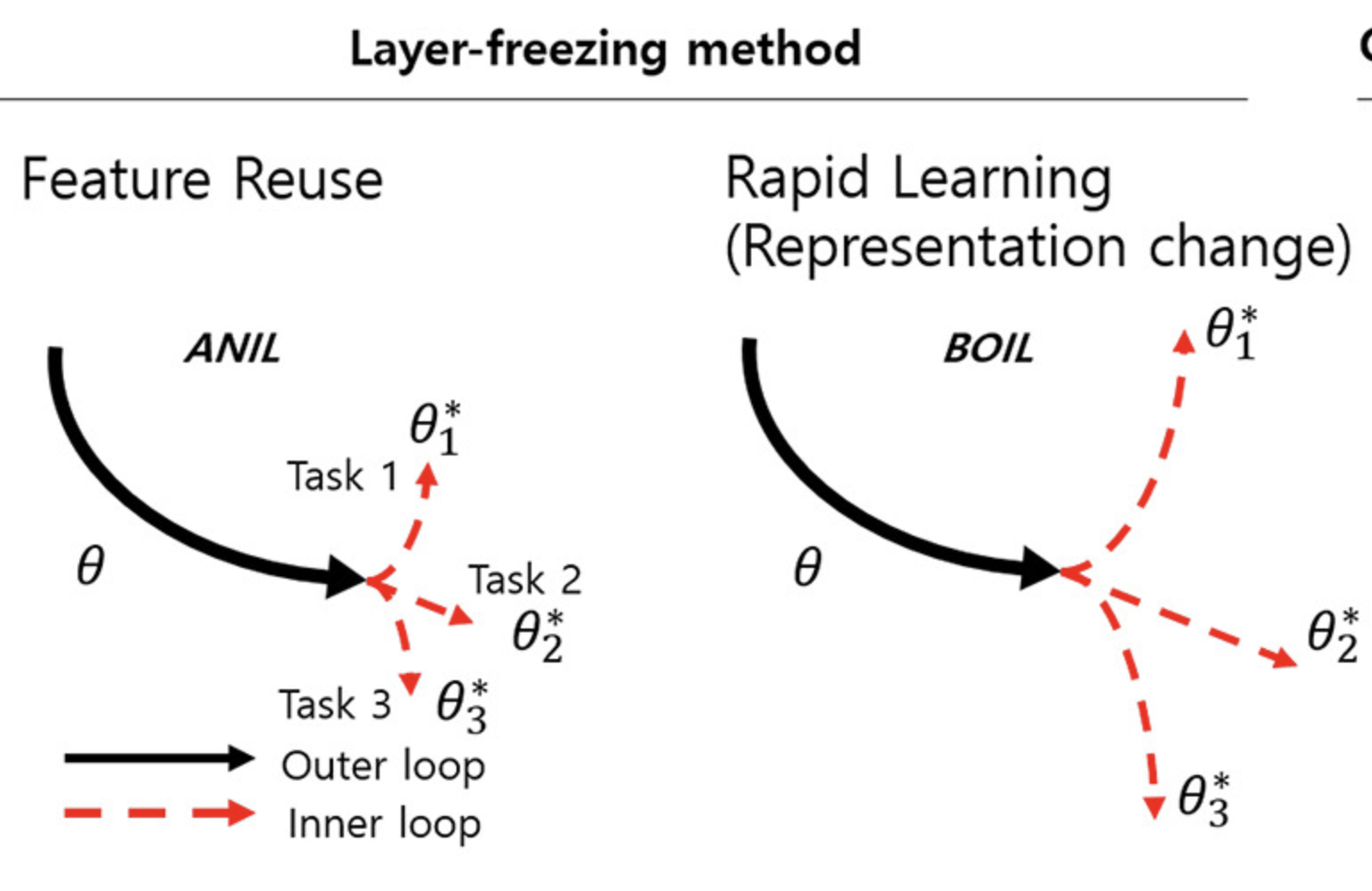
Jangho Kum, Junhoo Lee, Donghoon Han, Nojun Kwak Expert Systems with Applications 2025 paper / code GAIL (Gradient Adjustment in Inner Loop) improves few-shot learning by adjusting per-layer gradient updates based on priority, enhancing task adaptation. Unlike prior methods that either freeze or selectively update layers, GAIL aligns gradients across tasks for better convergence. Experiments show that GAIL outperforms existing inner-loop adaptation techniques in both speed and accuracy. |


|
Donghoon Han*, Eunhwan Park*, Gisang Lee*, Adam Lee, Nojun Kwak EMNLP 2024 Industry Track code / arXiv MERLIN leverages LLMs in a training-free, iterative feedback pipeline to refine text-video retrieval, significantly enhancing alignment between user queries and video content, with boosted improvements in Recall@1 across datasets. |
|
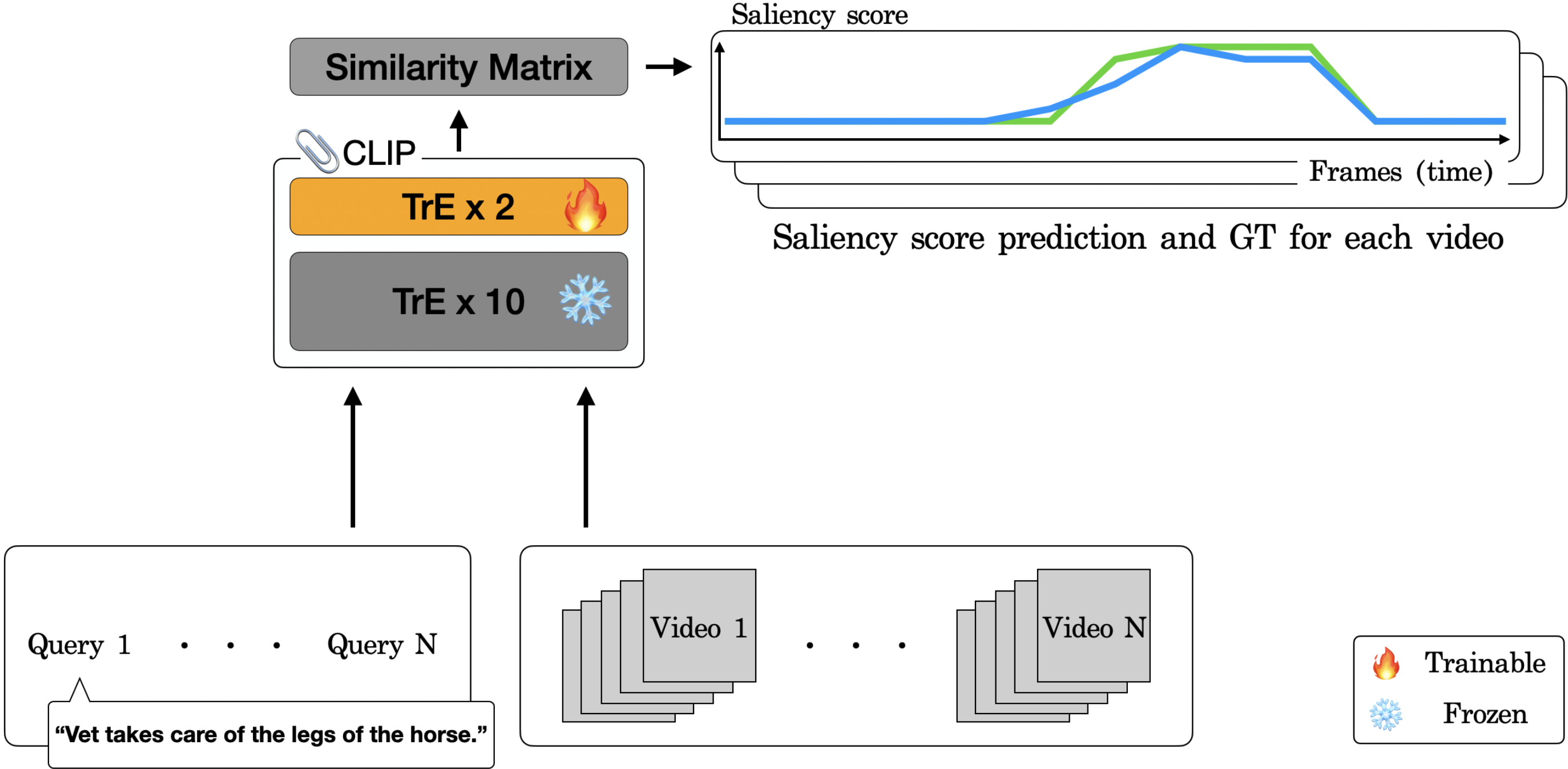
Donghoon Han*, Seunghyeon Seo*, Eunhwan Park, SeongUk Nam, Nojun Kwak CVPR 2024 Workshop on Efficient Large Vision Models arXiv We leverage the pre-trained multimodal model CLIP to achieve state-of-the-art performance in video highlight detection by fine-tuning the encoder and integrating a novel saliency pooling technique. |
|
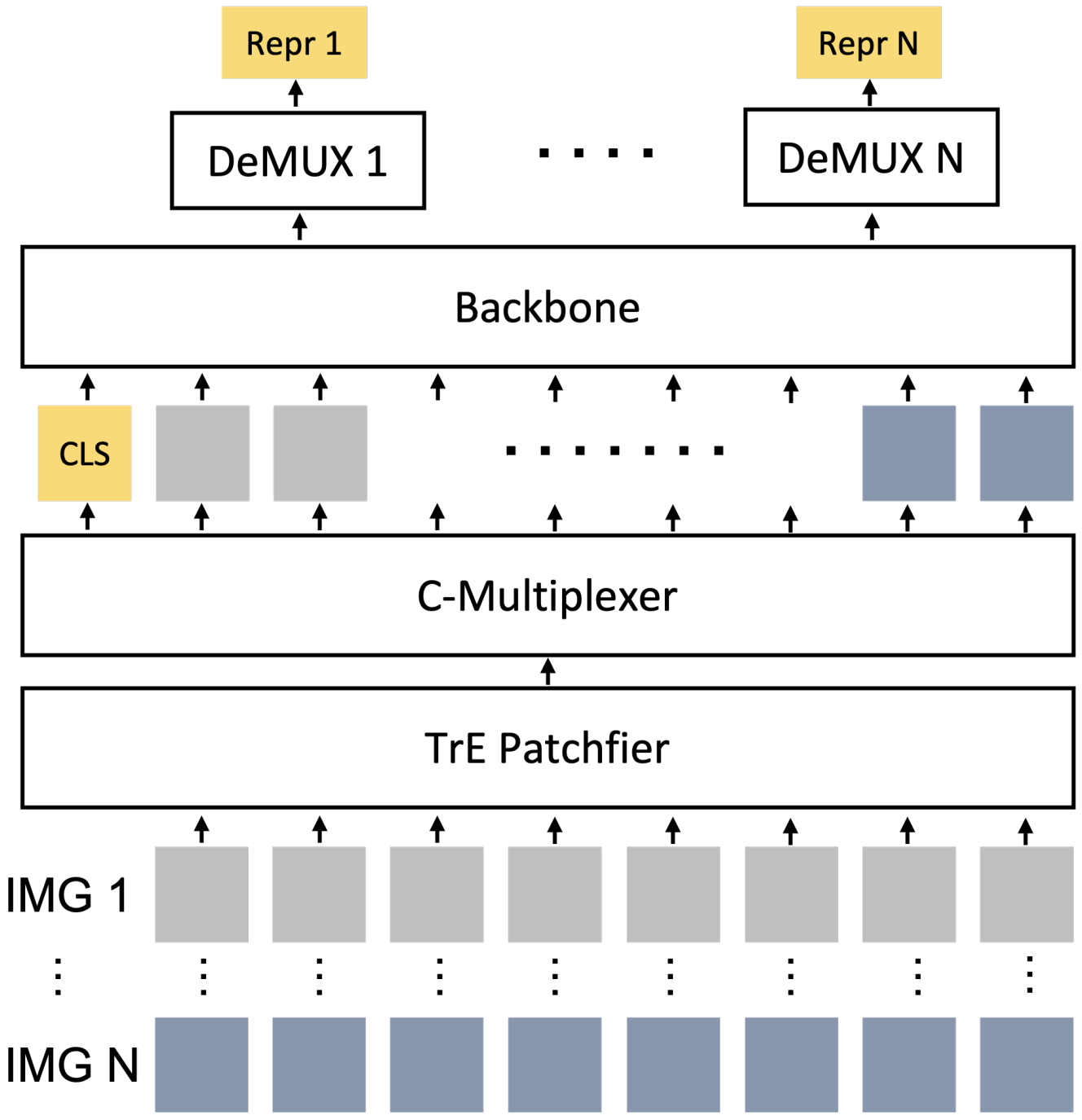
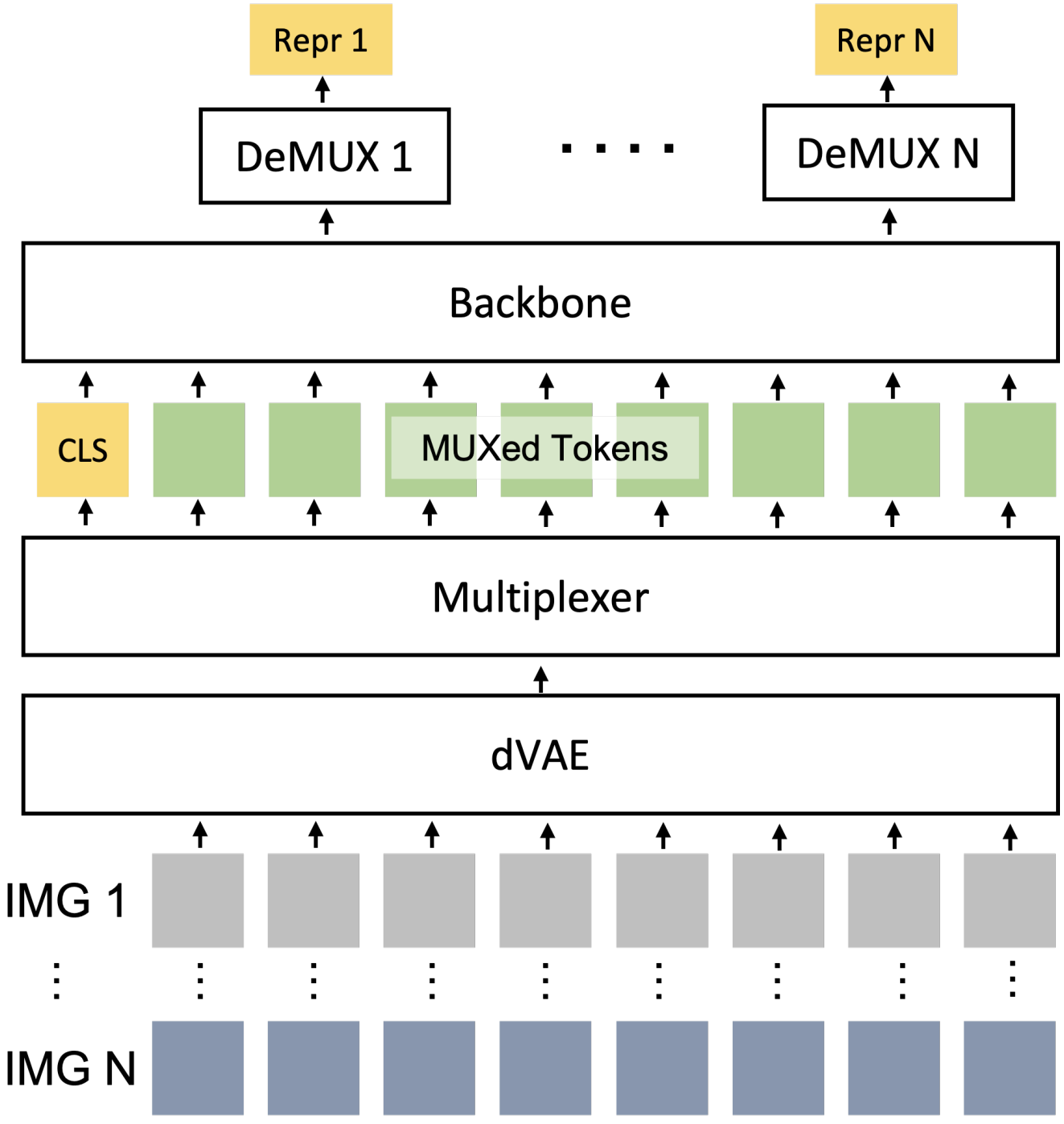
Donghoon Han, Seunghyeon Seo, DongHyeon Jeon, Jiho Jang, Chaerin Kong, Nojun Kwak NeurIPS 2023 Workshop on Advancing Neural Network Training (Oral) arXiv We expedite ViT inference by concatenating abstract visual tokens from multiple images along dim=1 and processing them collectively. |

|
Seunghyeon Seo, Donghoon Han*, Yeonjin Chang*, Nojun Kwak CVPR 2023 (Qualcomm Innovation Fellowship Korea 2023 Winner) project page / code / video / arXiv We model a ray with mixture density model, leading to efficient learning of density distribution with sparse inputs, and propose an effective auxiliary task of ray depth estimation for few-shot novel view synthesis. |

|
Chaerin Kong, Jeesoo Kim, Donghoon Han, Nojun Kwak ECCV 2022 project page / code / arXiv Instead of directly combatting memorization for few-shot (n<100) image synthesis, we propose latent space smoothing regularizations that empower the generator to produce diverse (perceptually continuous) set of samples. |

|
Seonguk Park, Jookyung Song, Donghoon Han, Nojun Kwak IEEE Access 2023 paper link This study reveals a significant limitation in multi-domain image translation models: the inability to perform effective recursive translations. The authors propose a simple solution using additive perturbations during training, which not only addresses this issue but also enhances overall translation quality. |
|
Saem Park, Donghoon Han, Nojun Kwak ICPRAM 2022 arXiv This study presents a new method for video frame interpolation using an invertible U-Net based Generative Flow, avoiding optical flow techniques. The approach maintains temporal consistency and image quality, offering a innovative baseline for video interpolation without traditional limitations. |
|
Thanks for sharing the website template, Jon Barron. :) |